
What are some of the most profound changes in the fields of computer architecture and hardware design that you’ve witnessed so far in your career?
The most profound shift I have witnessed over the past 25 years is the transition from general-purpose computing centred on the central processing unit (CPU) to heterogeneous, accelerator-rich systems. Early in my career, architectural innovation was largely driven by instruction-level parallelism and frequency scaling. As power and memory walls became dominant constraints, the field pivoted toward specialization, reconfigurability, and energy-efficient architectures.
Another major change is the rise of hardware-software co-design as a necessity rather than an option. Compilers, runtimes, and architectures are now deeply intertwined, a trend reflected in my work on FCUDA, DNNBuilder, SkyNet, and ScaleHLS.
The emergence of AI has further accelerated this shift, fundamentally altering architectural priorities toward memory-centric design, data movement minimization, and domain-specific accelerators.
Equally transformative has been the rise of open-source ecosystems and deep industry-academia collaboration. Tools and ideas now propagate far more rapidly, allowing research prototypes to transition into production systems, as exemplified by the adoption of our recent work, Medusa, in NVIDIA TensorRT-LLM. At the same time, AI itself is emerging as a powerful tool for architecture and system design, reshaping how future hardware will be conceived, optimized, and validated.
Which of your research results have had most impact?
Several of my research contributions stand out for their sustained impact across academia and industry. FCUDA was the first compiler framework to enable efficient translation of CUDA programs to field-programmable gate arrays (FPGAs). FCUDA created a new programming environment where both graphics processing units (GPUs) and FPGAs could be programmed using the same language in a heterogeneous compute system. This vision and effort preceded similar commercial OpenCL-to-FPGA flows offered by Intel and Xilinx by five to six years. It also significantly lowered the barrier for GPU programmers to leverage reconfigurable hardware. This work helped catalyse a broader movement toward productivity-driven accelerator design.
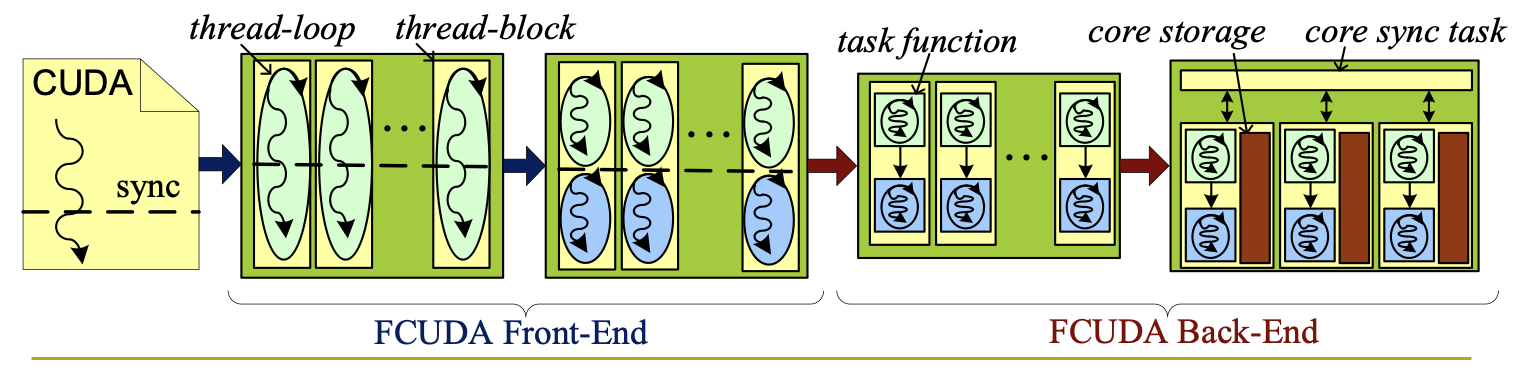 FCUDA was the first compiler framework to enable efficient translation of CUDA programs to FPGAs
FCUDA was the first compiler framework to enable efficient translation of CUDA programs to FPGAs
DNNBuilder and ScaleHLS represent another impact area. DNNBuilder enabled automated mapping of deep neural networks onto FPGAs, while ScaleHLS became the first compiler to map PyTorch models directly to customized FPGA accelerators. With thousands of downloads worldwide, ScaleHLS has influenced both research workflows and industrial prototyping.
As mentioned above, Medusa’s integration into NVIDIA TensorRT-LLM, delivering up to 3.6× inference speedup, exemplifies successful translation from research to production. Also, my A3C3 methodology (AI Algorithm and Accelerator Co-design, Co-search, and Co-generation) has had lasting influence by framing AI and hardware as co-evolving artefacts rather than separate optimization targets. Following the A3C3 design methodology, we developed the SkyNet model, which won double championships in 2019 in the DAC System Design Contest for both GPU and FPGA tracks for low-power image object detection, outperforming 100+ competitors worldwide. Later, SkyNet has been used by many other contestants and several companies.
 The A3C3 methodology promotes hardware-software co-design for holistic optimization
The A3C3 methodology promotes hardware-software co-design for holistic optimization
Finally, the startup company I co-founded, Inspirit IoT, Inc., recently launched a product called StreamTensor, a compiler framework that tackles the data-movement problem in AI hardware by transforming PyTorch models into optimized dataflow implementations. It includes a novel iterative tensor (itensor) type that systematically encodes stream information, describing how data moves, while the compiler identifies optimal tensor tiling, kernel fusion, and hardware-resource allocation. Based on FPGA evaluations on large language models (LLMs), StreamTensor achieves up to 0.64x lower latency and up to 1.99x higher energy efficiency compared to GPUs.
 StreamTensor, a commercially available product from Inspirit IoT, compiles PyTorch LLM models into stream-oriented dataflow designs for FPGAs
StreamTensor, a commercially available product from Inspirit IoT, compiles PyTorch LLM models into stream-oriented dataflow designs for FPGAs
What impact has the application of machine learning to the design of hardware had? What are some of the promises and perils of AI in hardware design and computing systems more generally?
This is a very timely question. Machine learning (ML) has begun to meaningfully influence hardware design by introducing data-driven techniques into design space exploration, hardware code generation, and system- and tool-flow optimization. In my own work, ML-based methods have been applied to accelerator selection, high-level synthesis optimization, and scheduling decisions, enabling systems to adapt more effectively to workload characteristics and design constraints. Although these approaches are still at an early stage, they already demonstrate strong potential to augment human expertise and significantly improve design productivity.
At the same time, substantial challenges remain. High-quality industrial design data suitable for training ML models is often scarce or proprietary, which limits model robustness and generalization. Hardware code generated by AI today can be incomplete or error-prone, raising serious concerns about correctness, verification, and trustworthiness. In addition, AI-driven design tools can make internal design decisions less transparent, complicating debugging, validation, and security assurance.
Recognizing both the promise and the challenges, in 2024 I co-founded the first IEEE International Workshop on LLM-Aided Design (LAD) together with Dr Ruchir Puri of IBM, which evolved into the inaugural IEEE International Conference on LLM-Aided Design in 2025. This venue focuses on leveraging LLMs to assist the design of circuits, software, and computing systems with improved quality, productivity, robustness, and cost efficiency. The conference has attracted hundreds of researchers and practitioners, many from industry, and has emerged as a highly impactful and promising forum. Looking ahead, while AI-assisted hardware design is far from a solved problem, it is well positioned to fundamentally reshape how hardware systems are conceived, built, verified, and deployed, provided these challenges are addressed through careful co-design, rigorous verification, and responsible deployment.
What are the most important requirements hardware must respond to in the AI era? How has this affected your approach to hardware design?
In my view, hardware in the AI era must address three dominant requirements: energy efficiency, memory efficiency, and adaptability. Modern AI workloads are increasingly memory bound, driven by massive parameter counts and the cost of data movement rather than raw computation. This shift has elevated the importance of memory-centric designs, near-memory computing, dataflow-based architectures, and high-bandwidth interconnects. As noted above, our recent work, StreamTensor, the first compiler to map PyTorch LLM models directly onto FPGAs, demonstrates substantial latency and energy efficiency gains by generating custom dataflow-based LLM accelerators that significantly reduce data movement (see StreamTensor figure on p.9). This approach has already gained notable traction in both industry and the research community.
Adaptability is equally critical. AI models evolve over a timescale of months, while hardware platforms evolve over years. This mismatch has reinforced my focus on reconfigurable and programmable architectures and compiler-driven specialization. My work on FPGA-based accelerators, heterogeneous systems, and dynamic reconfiguration reflects the need to maintain flexibility without sacrificing efficiency, allowing hardware to keep pace with rapidly evolving AI algorithms.
Finally, energy efficiency and scalability now dominate system-level design in the AI era. Hardware must operate efficiently from edge devices to large-scale data centres under strict power and thermal constraints. These realities have pushed my research toward cross-layer co-design, where algorithms, compilers, hardware, and systems are optimized jointly to maximize intelligence per joule rather than peak throughput. In this context, I recently planned and co-organized the National Science Foundation workshop ‘AI+HW 2035: Shaping the Next Decade’ and am contributing to a vision paper outlining a 10-year roadmap toward achieving a 1000× improvement in AI training and inference efficiency through deep integration across abstraction layers involving both AI model and hardware (HW) innovations.
 The NSF AI+HW 2035 workshop featured a keynote by Yann LeCun and leading researchers from academia and industry, including HiPEAC associate members Kunle Olukotun and Subhasish Mitra
The NSF AI+HW 2035 workshop featured a keynote by Yann LeCun and leading researchers from academia and industry, including HiPEAC associate members Kunle Olukotun and Subhasish Mitra
What role do you think open source will play in hardware development in the future?
Open source will play a foundational role in the future of hardware development, much as it has in software. As hardware systems become increasingly complex and heterogeneous, no single organization can innovate effectively in isolation. Open-source tools, benchmarks, and infrastructure enable shared progress, reproducibility, and rapid iteration across the community.
My own work reflects this philosophy. Our open-source frameworks such as FCUDA, DNNBuilder, ScaleHLS, SkyNet, CSRNet, and Medusa have achieved broad adoption, fostered community-driven improvement, and delivered real-world impact. These platforms also serve as powerful educational resources, helping train the next generation of researchers and engineers in modern hardware-software co-design practices.
Looking ahead, open source will be essential for addressing AI-era challenges. For both government and industry, open ecosystems reduce risk, avoid vendor lock-in, and accelerate workforce development. Through my leadership roles in the IBM–Illinois Discovery Accelerator Institute and the AMD Center of Excellence, I actively promote and support researchers in building and sustaining open-source ecosystems that deliver lasting impact to industry and society.